即使疼痛也要盡力觀察,不,愈是疼痛愈要敏銳觀察。失誤不是偶然的,出現失誤是因為我心裡有輕率和不成熟。如果不承認、改正錯誤,就會永遠像孩子般不成熟地活著。
-- <突圍思考>,曹薰鉉著,盧鴻金譯
回顧昨日點出來的兩大障礙:
self.state.is_done() 和 is_lose():判斷局面是否已經結束、是否輸了。這個,在遊戲系統的架構下,你代理人就儘管下棋,你輸了我會告訴你。所以這個用法,相當於蒙地卡羅三條件之一的判斷,實作起來也不太直接。self.state.next(action):只要帶入 action,就能夠使用 next 方法取得下一個遊戲盤面。這和我以遊戲系統為主的架構大不相同!我必須要從客戶端傳送行動給予伺服器,交由它判定之後,才能夠得知下一個遊戲盤面是什麼。換言之,意義非常不同,next 是代理人自己推算後續盤面,但是我這裡,在代理人沒有概念遊戲會怎麼變化的情況,它相當於是只能和遊戲系統互動,然後真實地造成了遊戲狀態的改變,而沒有純粹自己推算這種功能。先描述 is_done 或 is_lose 吧。同第十天所述,狀態碼得到 Ix04 或是 Ix05 的時候,就知道遊戲結束了。可是,如果把模擬中的遊戲終局當作遊戲終局,那也真的就結束了,弄假成真,模擬一次就沒了。這個部份在遊戲系統、伺服器端、以及代理人端都有相對應的調整。先描述與終局相關的部份的話,是我新增了 Ix09 當作模擬進行中,敵方獲勝,而 Ix0a 當作模擬進行中,我方獲勝。這麼一來,就可以讓代理人有辦法好好統計結果並且更新節點。
這兩個模擬終局狀態碼,完全沒有被安插在遊戲系統中
$ grep Ix09 -R ./src/
這是一片空白。不過當然,我還是有放在 status_code.rs 裡面:
...
10 => return "SIM_MYSELF_WIN",
9 => return "SIM_OPPONENT_WIN",
...
但是因為沒有人在使用這個解析狀態碼的函數,這裡也就相當一個靜態的文件。實質上,負責與代理人以這兩個模擬終局碼互動的是遊戲伺服器,就位在先前也節錄過幾次的 handle_client 函數裡面,
// old camp: This is important information.
// Previously we make the variable `possible_change` for accomodating
// the shift of actions (and of course, game steps). Unfortunately,
// we didn't consider that camp can also shift across turns.
// With `oc` here, we can always compared the current camp, and thus
// determine the status code without maintaining the impossible
// state machine.
let oc = g.turn;
'simulation: loop {
// A state machine for RL support mode
// This way, when an "Ix02"/"Ix00" is encounted,
// this agent keeps occupying the server by staying
// in this loop, but use a different initial code to
// indicate the situation.
let es = if g.savepoint {
if g.is_ended() {
if oc != g.turn {
// simulated myself's win
"Ix0a"
} else {
// simulated opponent's win
"Ix09"
}
} else {
...
註解的內容有點劇透,不過也沒有關係。總之,在這個模擬主迴圈('simulation)開始之前,就會紀錄當前盤面該誰下的資訊在 oc 裡面。這個在之後供對照。進入迴圈之後,es 是歷史上我一直有一個空白狀態碼(Empty Status code)用來和重新開始每一個標準回合的代理人打招呼,但是這裡賦予了新的意義,當然,就造成了應當重新命名變數但未命名的現象。無論如何,如果現在遊戲處在模擬的狀態(也就是,在先前的某個時刻,代理人執行了 SAVE,然後它設定的模擬次數還沒達成),而且,遊戲結束了(g.is_ended(),直接呼叫遊戲引擎判定),再而且當前回合(g.turn)不是先前紀錄的自己的回合,那麼就將這個狀態碼設定成 Ix0a,代表自己勝利;因為遊戲系統的實作是,實行一個標準回合之後,棋局將輪到對手進行;既然這裡是剛結束,又是對手的回合,那就表示是先前的那個標準回合的勝利,也就是自己的勝利。反之,就是對手的勝利,Ix09。
代理人(初次登場的 examples/coord_clients/reinforcement_simulator.py)針對這兩個動作,
elif data[0:4] in (b'Ix09', b'Ix0a'):
self.num_trials = self.num_trials - 1
if self.num_trials <= 0:
self.action = CLEAR
self.simulation = False
else:
self.action = RETURN
...
self.update(-1 if data[0:4] == b'Ix09' else 1)
就會執行昨日我們看到過的、伺服器的 reset 函數的這兩組觸發條件。碰到一個模擬的終局條件,算是完成了一次嘗試(num_trial)。
這還算是簡單的。但另外一個困難的是 next 的完整效果。這個模擬下個盤面的功能,可不是只針對自己而已,它必須是能夠具備規則知識的遊戲基礎引擎。以圍棋或是井字遊戲為例,它理所當然的要去操作對手的棋步,否則總不能每次都模擬自己就無以為繼。疫途遊戲雖然在一個標準回合中必須產生多重連續著點,但也終究會走到對手的回合,屆時的調整是,對手的盤面的價值越好,對我們來說就越糟,反之亦然,所以需要操作一個負號。因此,這裡我也新增了有別於 Ix03 (回合起始)的狀態碼,Ix07 和 Ix08,分別代表敵手的模擬回合(而不會觸發遊戲伺服器轉頭去與另外一位代理人對話),以及自己的模擬回合。這接在前述遊戲伺服器的片段之後,
let es = if g.savepoint {
if g.is_ended() {
...
} else { // 如果還沒結束的話
if oc != g.turn {
// simulated opponent's turn
"Ix07"
} else {
// simulated myself's turn
"Ix08"
}
}
} else { // 如果並非模擬的一個標準回合的起始
"Ix03"
};
if stream.update_agent(g, &ea, &es) == false {
return false;
}
在代理人端,這個值會影響到前述的價值的正負號,
elif data[0:4] in (b'Ix01', b'Ix03', b'Ix07', b'Ix08'):
if data[0:4] in (b'Ix07'):
self.is_me = False
elif data[0:4] in (b'Ix03', b'Ix08'):
self.is_me = True
...
is_me 在後續的 update 過程中扮演著重要的角色,
def update(self, result):
coef = 1.0 if self.current_node.is_me else -1.0
w = 0
if result == 0:
state = np.frombuffer(self.current_node.state[4:], dtype=np.uint8)
state = torch.from_numpy(np.copy(state)).float().unsqueeze(0).to(self.device)
_, _, w = self.model(state)
else:
w = result
w = float(w) * coef
self.current_node.update(w)
result == 0 的時候,是表示並非終局,而是觸發「該節點尚未展開子節點」的條件,但不確定真正的回饋值,所以是進到這個更新函數,由第一個區塊使用 self.model 進行推論;反之,則看是勝或負的狀況,傳入此時的勝負值。
上述的兩個關鍵功能就能完成將蒙地卡羅移植到這個系統上的工作,但我再補充描述一下兩個參數:
TRIAL:就是模擬幾次(探索了整個展開的遊戲樹、碰觸到幾次折返點)的意思。DELAY:延遲啟動模擬。如果是 0 的話,就表示初手就會開始模擬;如果是任何大於 0 的值,就代表會等到那樣的手數過後,才開始模擬,在那之前則隨機下。昨天提到模擬太耗時,給各位讀者一點概念,這是驗證第十九代的時間:
而模擬對局的話,需要收集每一個著手的子節點探索分佈,以及最後的勝負,通常會掛著一個晚上來收集。
目前又遭遇到的意料之外的展開,先上圖,明天再在月光下慢慢探究...
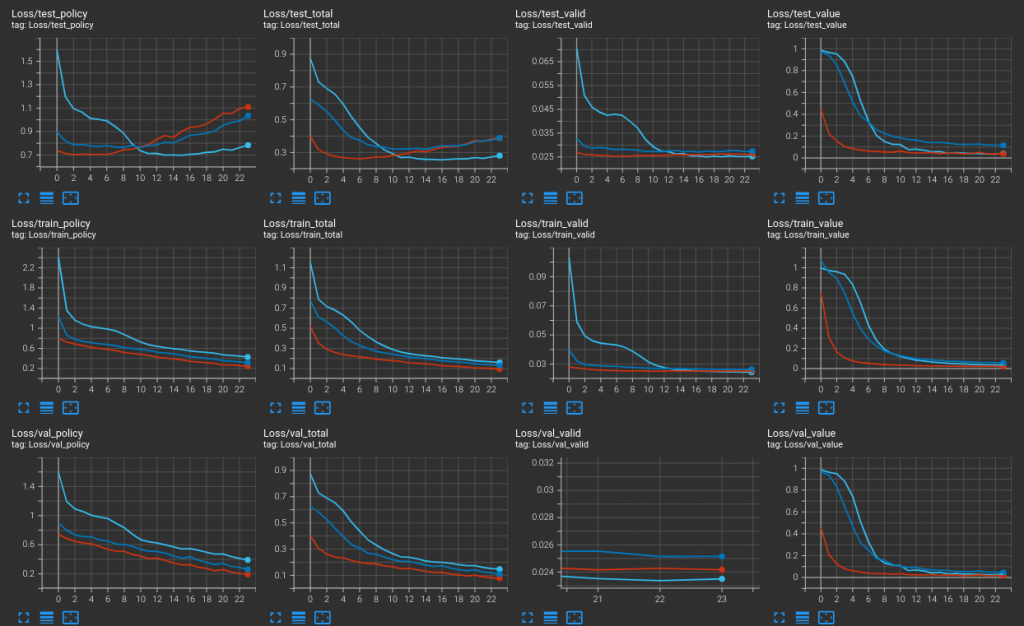
也再盤點了一下主題,看來,實作可遊玩網頁介面需要比我想像中投入更多工夫才行,要是不趕快進行,恐怕到時候會沒有東西可以玩。況且,我還希望可以連同 Windows 環境一起打通,這樣才方便分享給其他朋友,但是 Windows 上的 Rust + Web,又是另外一個挑戰了。
無論如何,這樣看起來應該可以剛好是最後三、四天當作附錄收尾的狀態。


 iThome鐵人賽
iThome鐵人賽